Open Sourcing the code to your SaaS is insufficient to make it actually be Open Source. Sounds self-contradictory?
Most services that espouse “Open Source”, do so by simply throwing the code over the wall. It’s better than nothing, but really misses the point that powers Open Source: enabling users to make a change to the software they’re using.
Some other popular services powered by Open Source software, such as GitLab.com or ElasticSearch do include the tools used to operate/deploy their service. Pause for applause
👏👏👏
But that’s also insufficient to actually enable users to become contributors effectively.
Much of the value of a service comes from things other than the code. It comes from the infrastructure it runs on, the operational processes, the monitoring, the backups, the metrics, the high availability, the scalability. It comes from data, from the network effect, with other users, with other interconnected services, with integrated tools, from legal agreements, and so on.
Any non-toy Service is not reproducible.
Launching a clone of the service in order to effectively contribute is a high barrier. Certain kinds of contributions clearly are possible. But contributors are essentially asked to “fork” the above non-code aspects of the service in order to iterate on their changes against their real world use cases.
What’s more, without true Open Source principles, we are missing a way to have a community develop with a center of gravity around the service itself. This leads to companies forking the service in a way that typical open source projects with a true community are resilient to.
I believe that if we enable contributions to services, rather than just the software, we reap the advantages of true Open Source. That means enabling users to make a change to a running service and experience that change themselves.
You still with me?
Yes, that means opening a pull request against a running service and experiencing that change before it’s merged.
This is not as insane as it sounds.
It appears that every technique we need to enable such a capability is already in use in modern deployment and operations methodology. We just have to connect the dots.
Why should I care?
I’ve been a part of Open Source for over 20 years now. Although I’m just one contributor, together we’ve changed something fundamental about the world. Our lives are too short, and software too complex, to have one company or one individual invent everything from scratch. So we work together across humanity to accomplish what no individual team could. This is our legacy, and it has become common place.
And yet there’s a very simple principle that drives Open Source:
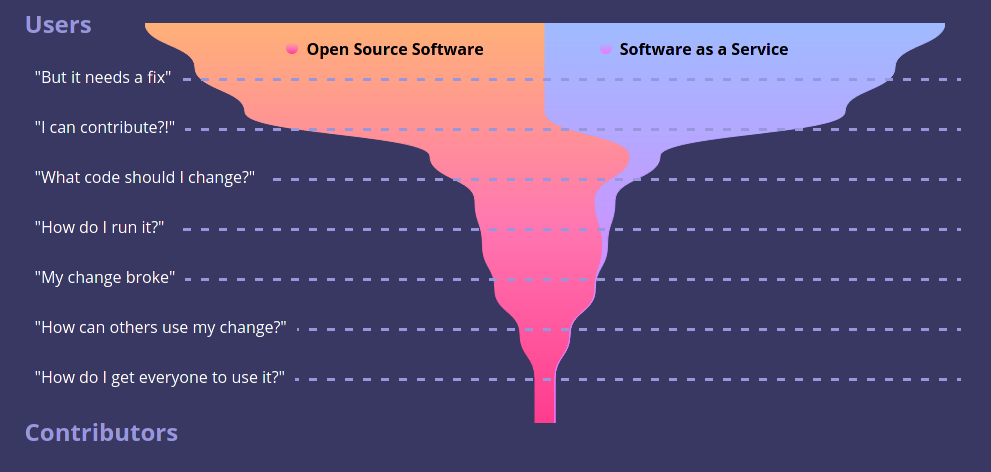
small percentage of users into contributors.
If you interrupt that principle, you starve Open Source. Software as a Service does just that: When someone else runs software for you, the intuitive mechanisms for users to change that software are unavailable.
“But” you may say, “If the source code for that running service was open then I could still change it.”
Sure you could change the code in some component, but for any reasonably complex Service you wouldn’t be able to run your changes, experience your changes against real world workflows, much less iterate on them until they’re good enough to share with others.
In reality the threat here is far more fundamental: Users of services cannot readily change something in the service not only because the processes are operated by someone else … but because such users of a service have explicitly chosen not to be involved in operating the software.
If the primary way to use Postgres was “as a Service”, then that (fabulous) project would be starved for contributors. This is because the number of contributors in a such a project are a function of some small percentage of users deciding to try to make change.
As this mechanism for using software, as a service, takes over the world the pool of users who can contribute to Open Source shrinks dramatically.
For a long time I saw this as a fundamental threat that would starve Open Source. I was unable reconcile Software as a Service with a healthy Open Source ecosystem.
But recently, I’ve become convinced that if we enable an effective contribution model on a service, one that doesn’t require that the users themselves become operators of the service … then we can reconcile this threat and Open Source will thrive on services instead of be starved by them.
You want me to do what!?
To enable contributions by users of a service, users that have explicitly chosen not to operate the software themselves, we have to set up a process by which they can make a change to a running service and experience that change themselves before others do.
For example, a user of such a hypothetical service should be able to:
-
Discover which component of a service to contribute to.
-
Make a non-sensical change (like add a printf style log statement) or change the spelling of a word.
-
Experience that change when they use the service, or when it acts on their data.
After discussing this with others, I firmly believe we have all the techniques we need, whether canary deployments, load balancing, continuous delivery, infrastructure as code, and so on. It’s been hard to find a single problem that an existing practice doesn’t solve.
It turns out many experienced engineering teams have come to that same conclusion. Rapid deployment of changes to services is a powerful capability highly sought after. For example, GitHub deploys changes before they’re merged. Whereas Facebook rapidly deploys changes to a few canary machines and scales each change up to production. Everyone has their own version of continuous delivery. It’s hard to take an engineering team seriously if they haven’t figured out how their team members can get a change rapidly deployed.
As Open Source, we have all the ingredients to have a decisive advantage here. To effectively collaborate on Open Source Services, contributors across humanity.
Lets try to craft a playbook to achieve this basic capability that drives Open Source Software and apply it to Open Source Services: The ability to change code and interact with that change … on a service.